# NAT Auto Scaling Group
This blog post is about approaches to NAT (opens new window) (Network Address Translation) in an Amazon Web Services (opens new window) VPC. The main motivation behind this example is maintaining Reliability (opens new window) whilst looking for Cost Optimisation (opens new window).
In small scale development environments a NAT gateway (opens new window) is a disproportionately expensive component. It costs around $36 per month, assuming very little actual data transfer and that the bulk of the cost is simply the hourly charge. The cost could be reduced by deleting and recreating the gateway if it's not used all the time, but this is a bit fiddly.
A NAT instance (opens new window) utilising a t3.nano and on demand instance pricing comes in at around $5 per month, and turning this off to save money is trivial. However, the naive NAT instance approach that is often deployed comes with some weaknesses; not least a comment hidden away on the Comparing NAT Instances (opens new window) page, which when talking about availability states "Use a script to manage failover between instances", is often overlooked. These weaknesses are described later on.
This blog post aims to both describe and demonstrate an extension to the NAT instance approach, which at the cost of a small amount of complexity (for which code is provided later) provides:
- Better fault tolerance
- Better availability
- More flexible pricing models
- Better cost performance
# Availability / Fault Tolerance
A NAT gateway is a highly available platform component.
A NAT instance (any EC2 instance) is not, and failure should be planned for.
Many NAT instance implementations just have a single instance launched, and if the instance were to fail then manually replacing it would be necessary. This is often sufficient for a short term manually stood up environment for a single person, however it doesn't really follow any best practice. If the environment is going to be around for a while, or shared by more than one person, then a more fault tolerant approach has some appeal.
Another motivation is that spot instances give very significant savings (up to 70%) over on demand instances, and it's not possible to utilise this pricing model if you are sensitive to failure. That same t3.nano instance running as a spot instance is approximately $1.3 per month.
A more fault tolerant approach places the instance into an auto scaling group (of size 1) so that it will heal itself. This comes with no extra cost, but with some extra complexity, as the route tables need to be updated when NAT instances are changed.
This isn't actually highly available of course, merely fault tolerant. It still experiences downtime, it's just that the downtime is a couple of minutes, not until someone can log in and figure out what has happened. It's also possible to deliberately set the size to zero to save money during off hours.
Anecdotally this approach has been used on small spike and proof of concept type environments, with a small number of developers using the environment intermittently. An auto scale down(off) at 0100 was introduced, and developers given permissions on the resize function so that they could bring the environment online again if they were working late. This reduced the monthly cost of the networking infrastructure from $36 to less than $1 per month.
A highly available implementation could involve multiple NAT instances, but at some point the cost/availability/convenience equation swings back in favour of the NAT Gateway. This isn't explored in any detail to try and keep this blog post simple.
# Challenges
The creation of the launch configuration and auto scaling group is easy and doesn't pose any problems. The only real complication is the updating of route tables.
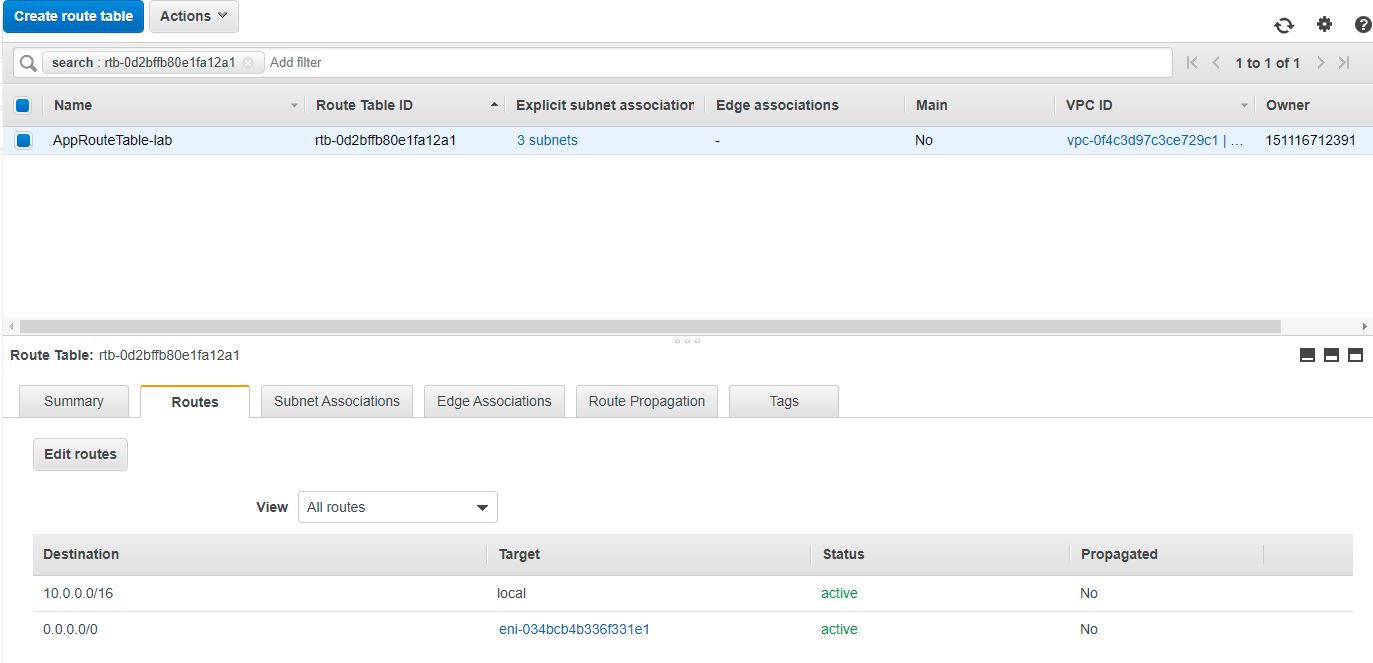
When using a NAT instance routes must be added to private subnet route tables, directing all traffic destined for the internet to the ENI (opens new window) of the NAT instance. When an EC2 instance is replaced in an auto scaling group it will get a new ENI. The route table will point to an ENI that no longer exists, and the traffic will be blackholed. Whenever a new NAT instance is launched it's necessary to update the private subnet route tables to route traffic to the ENI of this new NAT instance. In order to solve this problem we must:
- Detect the launch of a new NAT instance
- Detect which route tables require updating
- Update the routes in the appropriate route tables.
This can fairly easily be done with:
- EventBridge Events
- Tags
- Lambda
# Lab Example
A worked example of this approach is available on github here: Code Example (opens new window). The ReadMe within the repository describes how to use it. In an effort to make the example as easy to follow as possible the cloudformation has been split into two templates:
lab-nat-vpc.yml creates an example VPC for this lab. It creates the VPC, Subnets, Route Tables, Associations between Route Tables and Subnets. This isn't particularly interesting for this lab, and has been separated out to make the second file easier to read.
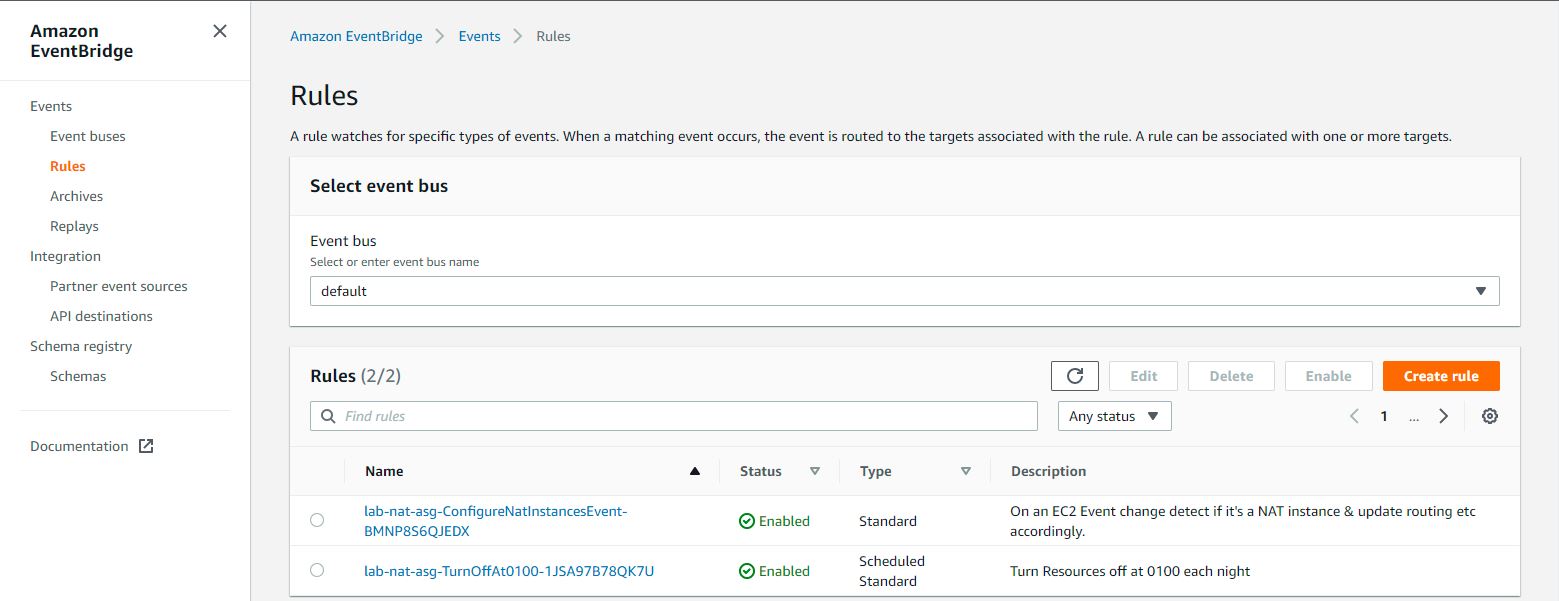
lab-nat-asg.yml contains an implementation as described so far. It creates a launch template and an auto scaling group for a NAT instance, Lambda functions to update the route tables, and resize the auto scaling group, and Events that trigger on an EC2 Instance Launch, and on a schedule at 0100 every day.
N.B. The ImageId for the Amazon Machine Image for the NAT instance provided is valid for the London Region. If you are creating these resources in another region you will need to override the default value for this parameter.
# Trying it Out
Once you have created the two cloudformation stacks you will have a running NAT instance, in an auto scaling group of size 1. The private route tables will not have been updated yet, as the lambda will not have been triggered.
Creating the JSON in the format of the EventBridge event to trigger the lambda manually is much more fiddly than just terminating the NAT instance.
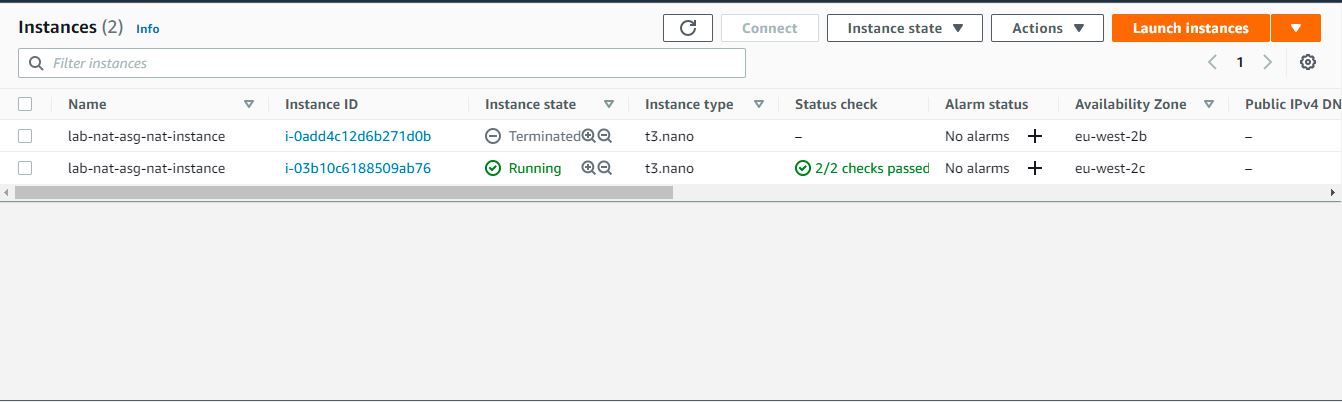
Terminate the NAT instance from within the AWS Console. You'll see a new instance launched to replace it, and a route get added to the private route tables pointing to it's ENI.
Here are some screenshots of what you should see in the AWS Console:
# Cloudformation Stacks

# Lambda
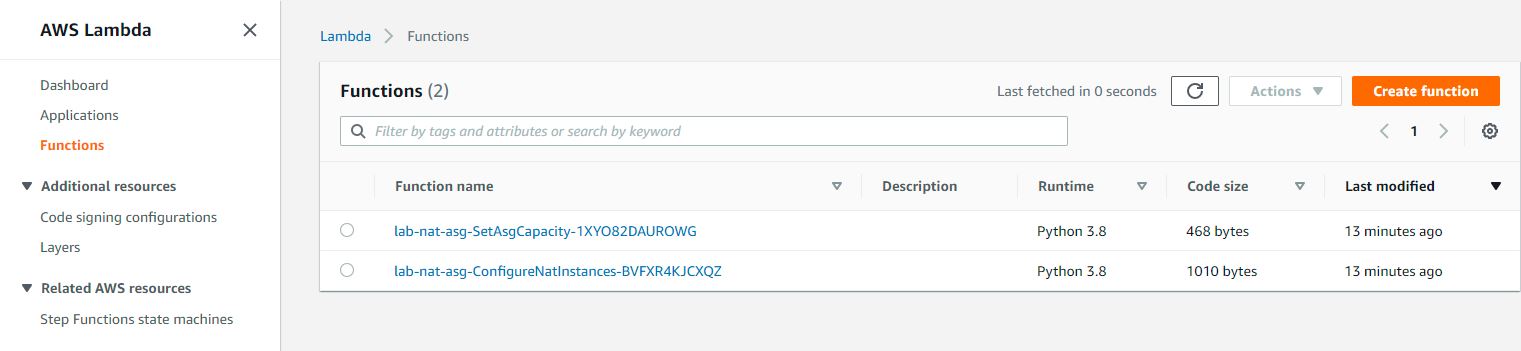 N.B. The names of the lambda functions are generated, the suffixes are expected to be different.
N.B. The names of the lambda functions are generated, the suffixes are expected to be different.
# EventBridge Rules
# EC2 Instances (after)
# Route Table (before)
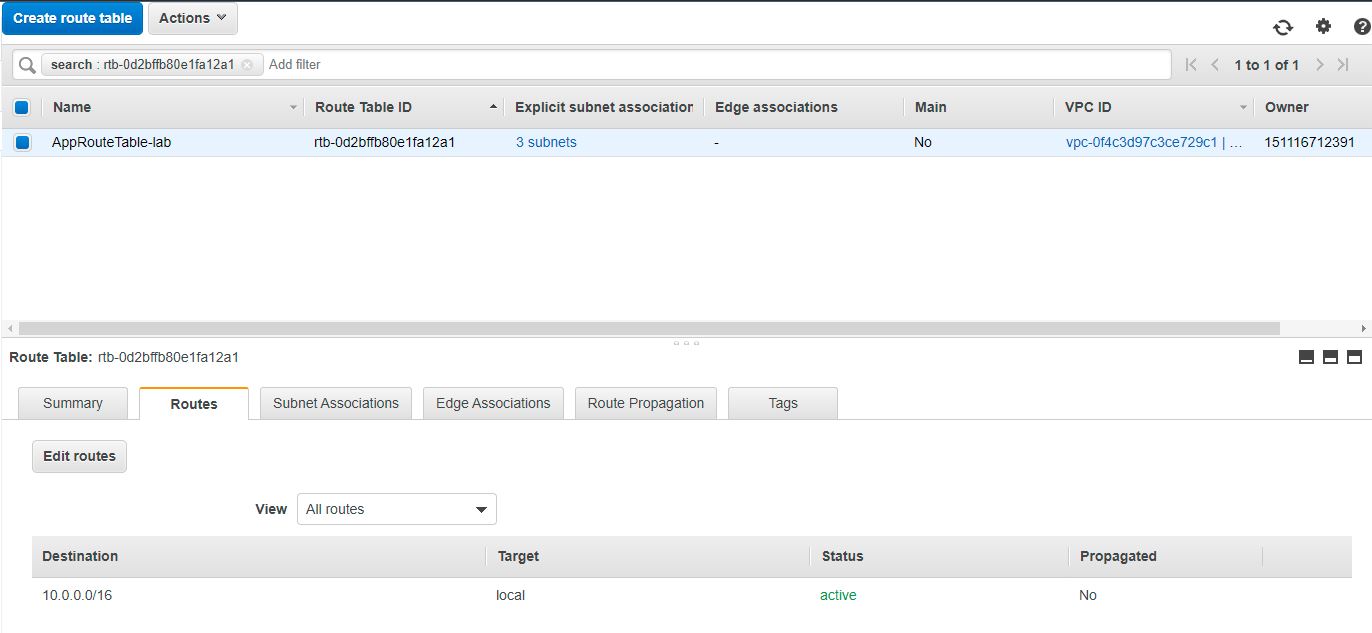
# Route Table (after)