# Database Deployment
In this blog we are going to explore database deployment applications and how they work. This being part of the "Data The Hard Way" series we will create a deployment utility (opens new window) from scratch, after all, how hard can it be?
We will start by framing database deployment within the context of the wider database development life cycle. This will cover common database activities and some examples of end to end processes that we have seen implemented. If you are already well aware of such topics, and want to jump straight to building a deployment utility, you can safely skip to the Requirements section.
Throughout this blog we use the terms database deployment application and database deployment utility interchangeably, but we do try to term the feature complete applications we reference as applications, and our little example as a utility.
# Introducing Deployment
Database deployment is one of three common activities when developing databases:
- Producing a model
- Comparing two different models
- Deploying updates and changes
1) Model
Producing a model is often done in an Enterprise Architecture, Software Architecture or Entity Relationship Diagram tool of some kind. Sparx Enterprise Architect (opens new window) and Erwin (opens new window) are two such applications. These tools often include functionality to publish the model to a database engine, or to produce a set of SQL scripts that implement the model but hold short of deploying them to a database engine.
2) Compare
Comparing two models to see the differences between them is often referred to as a "schema comparison" operation. It is sometimes more colloquially referred to as producing a "diff". This process looks to describe the changes from one model to the next, either simply as changes, or more often the set of updates that would need to be applied to one model, to make it match the other.
Applications such as Migra (opens new window), Postgres Compare (opens new window) and SQL Compare (opens new window) have this functionality.
3) Deploy
Deployment is the process of making changes to a database; either the initial deployment starting with an empty database, or ongoing incremental changes. Database deployments are also sometimes referred to as applying "migrations", or "patching".
Applications such as Flyway (opens new window), SqlPackage (opens new window) and liquibase (opens new window) have this functionality.
N.B.
We reference a lot of different applications throughout this post, not just in this section. Where we pick particular applications, this isn't indicative of an endorsement, recommendation or preference, it's just an example. There are lots of good tools out there, all with their own features, design decisions and quirks.
It's worth noting that many of these applications have functionality that covers more than one of these areas. The examples listed so far are chosen to be illustrative but are by no means exhaustive. Indeed SQL Server Data Tools (opens new window) was omitted above as it covers all three areas without such an obvious leaning. Sparx Enterprise Architect allows you to design models, import a model from a deployed database, publish a model to a database engine and compare a model to a deployed database. However, it lends itself much more towards the building of a model, than integrating with a deployment process. Applications such as Flyway (opens new window) and liquibase (opens new window) are more suited towards deployment as they are easier to integrate with source control systems and CI/CD (Continuous Integration & Continuous Delivery or Deployment) pipelines.
Database source control, automated deployments and CI/CD processes are very interesting topics in their own right. This blog is a deep dive into the deployment process, so we won't discuss them further here.
# Definitions
Some terms can be ambiguous, or overlap considerably depending on context. In an effort to be consistent throughout this post we will adopt the following terms:
| Term | Definition |
|---|---|
| Model | A model of a database. Not necessarily deployed anywhere. This generally represents the "target", "to be", "future", or "next" version of a database. |
| Database | A model when deployed to a database engine is referred to as a database. |
| Diff | The difference between a pair of databases or models. |
| Drift | Unintentional differences between models or databases. Where changes to a database have been made outside of the deployment process (whatever that is). |
| Script | In this post a script means a SQL Script. |
| Deployment | The process of taking a database from its current version to a target version. This is the process of applying a number of scripts. |
# Processes
If the output of a database implementation is useful then there will be requests for enhancements over time. There needs to be some way of getting those changes published or deployed.
There are lots of ways that the database activities listed above can be arranged in a process that takes an idea for a change through to being deployed. Creating a model has to be at the start. Deployment has to be at the end. Between these two steps operations can be chained together in any order that suits the needs of the organisation / business / particular use case.
Common adjectives that come up when talking about desirable database deployment processes include:
- Safe
- Consistent
- Reliable
- Predictable
- Fast
Without being too concerned at this point as to which steps are manual and which steps are automated, here are some processes we have seen:
# Livin' on a Prayer
There is no model as such. There is a loose collection of SQL scripts on someone's desktop. Executing them in some order, discovered after trial and error will almost recreate the database.
Some changes that didn't get saved are missing and have to be re-implemented from memory.
# Development in SQL
The model is defined in a series of SQL Scripts maintained in a source control repository. Developers work on the model in the sql language itself using any text editor or IDE they prefer. A series of incremental patches define all of the tables and indexes to be created in the database. A series of repeatable patches define all non-data objects (views, functions, procedures etc) to be applied each time the database is patched.
A compare process isn't required as developers are committing incremental patches. The code they commit is effectively the result of a compare operation from the current version to their new model.
A custom-built patching application handles database deployment, and is reasonably closely aligned with our example. The application has a configuration file and runs through pre patching, patching, and post patching sections. In the pre-patch section all non-data objects are dropped and they are subsequently reapplied in the post patch phase. The application is much more fully featured than our example having GUI and CLI options, connection handling, authentication, logging & auditing, etc.
# Microsoft DacPac
A database model is managed as a SQL Server Data Tools Project using Visual Studio as an IDE.
Visual Studio produces a dacpac, which serves as the deployment package. This is still a model, but packaged in a format downstream applications can use, rather than for development in an IDE.
SqlPackage (opens new window) is executed with the Script action to create a record of what changes would be made. The content of this output is synonymous with a compare or diff.
SqlPackage is executed with the Deploy action to apply the changes to the database. This is the deploy phase.
N.B.
SqlPackage contains both comparing and deploying functionality, and it can combine them into a single step. In this example the steps were executed separately in order to keep a record of changes; the script step could have been omitted and its inclusion was a choice.
# Really Quite Complicated
A database design / entity relationship / enterprise architecture application is used to create a model of a database. This model is exported as an XML file.
A utility application parses the XML and uses a templating framework to create a SQL implementation of the model, adding and enforcing a series of standards and conventions as part of the process.
This implemented model is deployed as a database.
The previous version of the database in question is also deployed to a different database.
The previous version database and model version database are then compared using Migra (opens new window) to create a diff. This diff represents the difference between the previous version of the database, and the current (next) version of the database. This diff is saved as the next migration file, inside a data repository.
A Pull Request to a branch in the data repository triggers a pipeline, which deploys the latest version across a number of environments using Flyway (opens new window).
Where limitations in schema comparison tools cause problems they are worked around using before deployment and after deployment repeatable scripts.
# Others
There are really quite a lot of ways you could combine these operations and tools to create workflows and processes that work for you and your team. The "best" way to do it, depends very much on the organisation and team in question.
# Requirements
The first step in thinking about how we might implement a database deployment utility is to consider what it needs to do.
1) Databases are stateful; their main purpose is persistence of data (state). It must be possible to apply changes to the database incrementally as you cannot simply replace a database with a new version in the way you might application code. A script that creates a table will error if executed twice and dropping and recreating a table results in data loss. This requires the deployment utility to be able to remember which scripts have already been applied and not apply them again.
2) There are a lot of dependencies inside of a database implementation. Views, procedures and functions will depend on tables. This requires the deployment utility to be able to control the order of execution of scripts.
3) Some scripts will be idempotent, and as well as it being possible, it is also desirable to apply them multiple times. There are sometimes routine operations that we want to execute after every deployment. An example might be to loop around all tables and make sure their ownership is set correctly.
# Scope
Our deployment utility will cover the three requirements identified above:
- Track scripts that are not repeatable and ensure they are only executed once.
- Control the order of execution of scripts.
- Mark scripts as repeatable and execute them on every deployment.
In an effort to keep this example as clear as possible we will implement the simplest possible utility that meets these requirements. We will deliberately leave some things out of scope:
- We will limit the utility to targeting the PostgreSQL (opens new window) database engine only.
- We will exclude any tests from the code repository. The vast majority of tests will be integration tests and involve docker containers, database instances, and a load of boilerplate code that would dramatically increase the amount of code to read.
- We will deliberately omit from the logging implementation covering indexes and other database improvements.
# Implementation
The git repository for our code is here: Database Deploy (opens new window)
Our example has been implemented in python as it makes for very readable code. Something very similar could be created in most languages with more or less boilerplate and setup depending on the language. The first implementation of this was actually a bare bones powershell cmdlet supporting a very quick development spike.
There are only a small handful of files and folders in this repository:
| File | Purpose |
|---|---|
| ReadMe.md | The readme file for the repo, containing a link back to this blog post. |
| example-db (directory/folder) | Contains an example database to be deployed. This consists of a collection of four scripts and one configuration file. |
| example-db/config.json | This configuration file is a core part of the deployment utility. This is the interface between the database deployment utility and the user's database that needs to be deployed. |
| database-deploy-logging.sql | This contains a small handful of SQL tables to log deployment activity. These tables are part of the database deployment utility, not the user's database. |
| DatabaseDeploy.py | This is the entrypoint of the database deployment utility. It performs some basic error checking on inputs, and then calls the deployer class to do the work. |
| deployer.py | This is where most of the work is done. It is implemented as a python class. |
| requirements.txt | Dependency information, in this case just the psycopg2 library. See Also: pip (opens new window) |
N.B.
The definition of your database to deploy, and the source code of the deployment utility, wouldn't normally be in the same code repository. In the case of this blog, it is convenient to have only a single git repo.
Now that we have had a brief overview of the structure of the code repository the next few sections will describe the files in more detail.
# Config
We have elected to use a configuration file to control the order of execution of scripts. Another popular technique is the use of naming conventions; Flyway (opens new window) uses a naming convention based approach for this. We prefer a configuration file because it is easier to understand the changes over time in a text file, than it is to understand the presence or absence of files in a repository over time.
The format of this file would be a key thing to document if writing a deployment utility to be used rather than as an educational exercise! Our specification is very simple:
- A connection section giving the information needed to create a connection to a database engine.
- A list of file names split into "sections", each of which must have an isRepeatable indicator. This indicator controls whether the database deployment utility executes the scripts in that section on every execution, or just once.
There are some obvious limitations with this approach:
- It's common to want to deploy the same database to several different locations (local, development, test, production, etc). The connection section would be better in a separate configuration file on its own.
- There are more sophisticated ways of thinking about the life cycle events during a deployment activity. Flyway has the notion of CallBacks (opens new window) which illustrates this well. In this minimal example repeatable and non-repeatable scripts are sufficient for our needs.
# DatabaseDeploy.py
This is the entrypoint of the application. It performs some validation that exactly one parameter was passed, and that is the path to a file that exists. It then creates an instance of the deployer class to carry out a database deployment based on the contents of that configuration file.
# deployer.py
This class is where we have implemented a database deployment utility. At 107 lines long it is significantly shorter than the length of this blog post!
In the constructor for the class the configuration file is read into an object and stored in an instance variable. There are some helper methods over this configuration (get_sections, get_files) that exist just to hide away some of the json structure while in the deployment methods, in the hope it aids readability.
deploy
The most interesting method in the deployer class is deploy(). This method creates a connection to the target database, and ensures the tables required by the database deployment utility exist. These tables are the contents of database-deploy-logging.sql.
Once we have bootstrapped the deployment utility itself, we can proceed with deploying out the user's database objects. The process for this is quite simple:
for each section (in order):
for each file (in order):
execute that script (if it needs executing)
The first two lines of this pseudocode example are accomplished using simple iterators. The third line is accomplished by calling the is_repeatable_section method which will check the isRepeatable property on each section. If the section is repeatable then all of the scripts are executed using the deploy_repeatable_file method. If the section is not repeatable then the deploy_file method is called instead which ensures each file is only ever deployed once.
deploy_repeatable_file
This method executes the scripts every time. It does not log this activity into the logging tables, it just logs to standard out.
deploy_file
This method executes the scripts only once. This method logs the start, success and failure of each attempt, along with keeping a record of all successfully deployed scripts, so that they can be skipped over on future deployments. The check to ensure that we only deploy scripts once is contained in the is_already_deployed method; which returns true if the name of the script in question is present in the deployed table, indicating that it has, in fact, already been deployed.
# Other Implementation Notes
We deliberately only log the non-repeatable migrations as the repeatable ones will get executed numerous times and would result in a great deal of noise in the logs. Their very nature means in the case of failure you would correct and then re-execute.
- Repeatable scripts tend to be used for things like creating non data objects (views and functions).
- Non-Repeatable scripts tend to be used for altering tables and updating data. These are generally much more significant scripts which is why we elect to log this activity.
It's normal for database deployment applications that keep track of previously executed scripts / migrations or patches to store them in the database they are deploying to. We have followed this approach. In our case we have created our own schema to place this information on, which is also typical. In theory it would be possible to keep track of this outside of the database, but there's no obvious argument for doing so; the data is clearly related to that deployed database itself. If separated there is risk of the link between the record of deployed scripts and the database in question being broken. Losing track of which scripts have been applied to the target database would be a serious problem that is best avoided.
# Requirements Review
We will now cross check the implementation we have seen against our requirements:
| Requirement | Implementation |
|---|---|
| Incremental Updates | For all sections that are marked isRepeatable:false we log the deployment of those scripts and execute them once only. |
| Control of Order | Deployment follows the order of config.json. (Using OrderedDict, yes - it is that simple!) |
| Repeatable Updates | Sections marked isRepeatable:true get executed on each deployment. |
# Trying it out
The purpose of this blog was to learn by doing, and indeed by doing it the hard way. In this case we have created:
- an example database deployment utility
- an example configuration file
- an example database
You can alter literally any of it to see what happens. All the different parts have been kept as minimal as possible to make experimenting with it as easy as possible (at least that's what we were aiming for). Trying to make such changes to a complex application like Flyway would be difficult, or in the case of a closed source application like SqlPackage - impossible.
In particular, if you would describe your current approach as a bit loose then this is a great opportunity to really get into the nuts and bolts of how these tools work, and perhaps think about better ways of working.
Follow the steps in the table to try out using the utility. We've used it on both Windows 10 & Ubuntu 21 operating systems.
| Step | Comments |
|---|---|
| Prerequisites | On a system with docker, python3 & pip installed |
| Install the requirements | pip install -r requirements.txt |
| Run a postgres instance in a docker container | docker run -d -p 5432:5432 -e POSTGRES_PASSWORD=SuperSecretPassword postgres |
| Create an environment variable to contain the SuperSecretPassword | This is operating system specific |
| Update the config.json file connection information. | In particular align the name of the environment variable for the password |
| Run a deployment | python ./DatabaseDeploy.py example-db/config.json |
| (Optionally) Run a deployment | python ./DatabaseDeploy.py example-db/config.json On this second occasion you will see log entries related to "Skipping already deployed file" |
# Screenshots
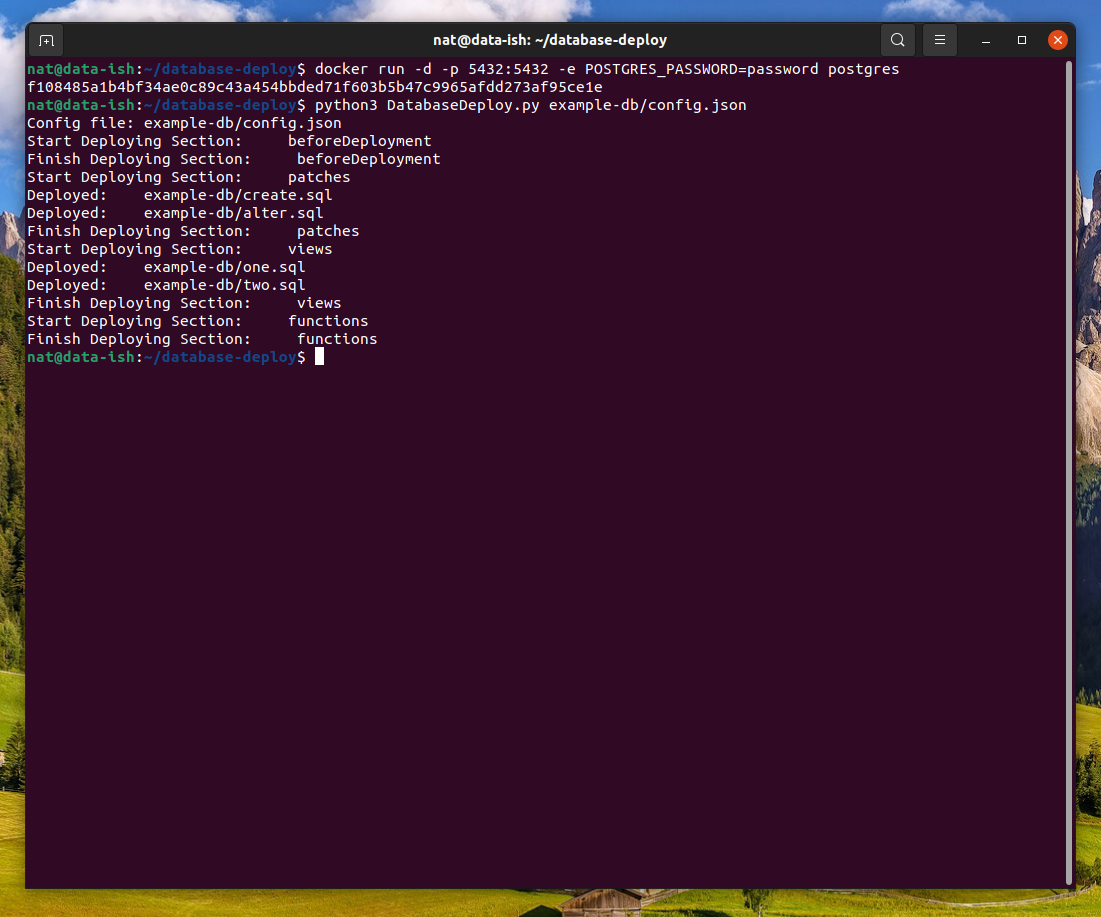
# First Deploy
The first time you run the deployment command you will notice that the two scripts ("create" and "alter") were both executed, as it's a fresh database instance and they hadn't been executed yet. The two views ("one" and "two") were also both executed.
# Second Deploy
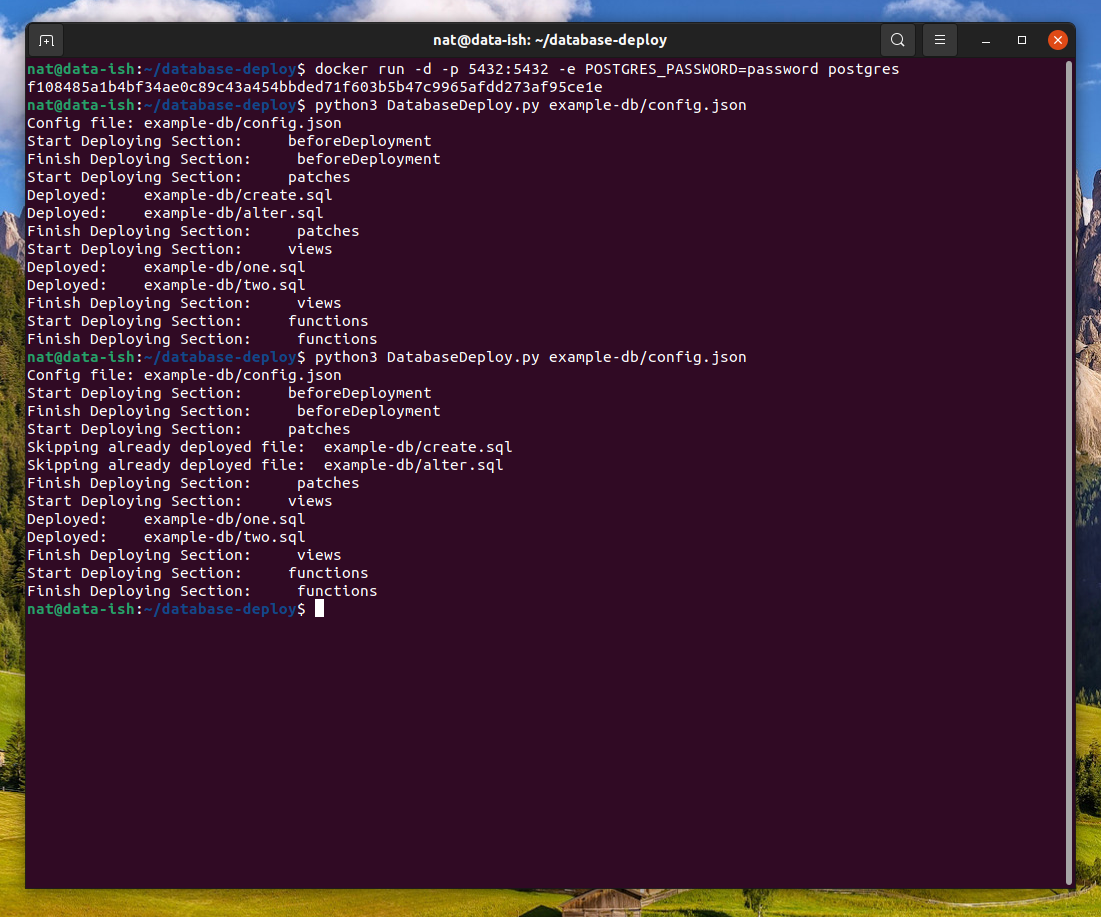
The second time you run the deployment command you will notice that the two scripts ("create" and "alter") were both skipped over, as they have been deployed before. If you examine the contents of those two files you will find that executing them again would cause a failure. The two views ("one" and "two") were both executed.
# Things to try out
Here are some ideas of things to try out to change/extend the provided example:
- The views are currently idempotent as they drop and recreate themselves. If you take out the drop statement the deployment utility should error. Does it?
- The non-repeatable scripts were logged into the table dbdeploy.deployed, this is preventing them being executed again. If you truncate that table the deployment should attempt to run them again and error. Does it?
- Add your own scripts, thinking about order and dependencies.
- Enhance the utility so that the connection configuration is separate, and you can deploy the same database to different instances.
# Finally
Hopefully this has started to reveal some of the "magic" in database deployment utilities. If you already had some kind of deployment tool in place but didn't really know how it worked, or why it worked that way, perhaps this has helped give some ideas.
If your deployment process is manually making whatever changes you like and hoping for the best, maybe this has suggested there is a better way, and hopefully it's made the tools already available seem more approachable.
Maybe none of that's true, in which case we hope that at least you found this interesting.
# Other Resources
# data-ish
# External Links
- Flyway (opens new window)
- Octopus Deploy (opens new window)
- Redgate Deploy (opens new window)
- SQL Server Data Tools (opens new window)
- Microsoft DacPac (opens new window)
- Microsoft DacPac Script (opens new window)
- Microsoft DacPac Publish (opens new window)
- Migra (opens new window)
- Postgres Compare (opens new window)
- SQL Compare (opens new window)
- Sparx Enterprise Architect (opens new window)
- Erwin (opens new window)